•
Author: Natasha Glover •
∞
I recently became aware of the memes and popular science articles going around the internet claiming that we share 50% of our DNA with bananas. For example:

Source: http://www.quickmeme.com/meme/36gnaz
I work in the Dessimoz lab at the University of Lausanne, and here we are in the business of comparing genes. In fact, I’ve had a similar question before一 what percentage of our protein-coding genes do we share with another plant, Arabidopsis thaliana. I computed the number as being closer to 17%.
I wanted to get to the bottom of this question once and for all: What percentage of a human’s “genetic material” is shared with a banana? There have been several other blog posts from scientists touching on this question (Neil Saunders: “50% bananas”, Stack Exchange skeptics: “Do humans share 50% of their DNA with bananas?”, Sanogenetics: “Are We Genetically Similar To Bananas And Why Is This Important For Research In Disease?”).
However, I wanted to go a little deeper into:
- Where this number came from, and the extent of it being spread on the internet.
- What exactly do we mean by “shared genetic material”?
- Some results I computed in attempts to put this controversy to rest once and for all.
In this blog post I will attempt to address these questions.
Where did the mythical 50% come from anyway?
After performing a quick google search, it seems that the relatedness between a human and a banana has been a popular question. With a cursory, non-exhaustive search, I show in the table below eight sources who report that 44-60% of the human genome is “shared” with banana.
| Source |
quote |
|---|
| Irishnews.com |
“But we are also genetically related to bananas – with whom we share 50% of our DNA – and slugs – with whom we share 70% of our DNA.” |
| getscience.com |
“Banana: more than 60 percent identical. Many of the “housekeeping” genes that are necessary for basic cellular function, such as for replicating DNA, controlling the cell cycle, and helping cells divide are shared between many plants (including bananas) and animals.” |
| thenakedscientists.com |
“So where does this banana statistic come from? Is it just complete nonsense? Well, no. We do in fact share about 50% of our genes with plants – including bananas.” |
| PopSci.com |
“Bananas have 44.1% of genetic makeup in common with humans.” |
| MythBusters (tv show) facebook |
“#sciencefact: Humans share approximately 98% of their DNA with chimps, 70% with slugs, and 50% with bananas! http://bit.ly/qsWX8p” |
| mirror.co.uk |
“Humans share 50% of our DNA with a banana.” |
| Business Insider |
“The genetic similarity between a human and a banana is 60%.” Source: National Human Genome Research Institute (However, no link and when I tried to search) |
| Sundaypost.com |
“Yes, and we share 50% with bananas. It’s not surprising, if you look at the basic mechanism of biochemistry.” |
What is disconcerting is that at least half of these sources come from popular science websites or science sections of newspapers, yet few have any sort of citation at all. The only exceptions were Popular Science, which gave DataScope as a source, and Business Insider, who cites the National Human Genome Research Institute. However, neither of these articles give a link or further information to follow up on.
Upon further digging, I found one recent article published on howstuffworks entitled “Do People and Bananas Really Share 50 Percent of the Same DNA?”, which contains an interview with one of the scientists from the Human Genome Research Institute, where he explains how they arrived at that number.
“Brody says the experiment was not published, as most scientific research is. Instead, it was generated to be included as part of an educational Smithsonian Museum of Natural History video called ‘The Animated Genome.’ That video noted that DNA between a human and a banana is ‘41 percent similar.’””
The article goes on to explain that this 41% figure comes from a blast search between protein sequences of human and banana. They found about 7,000 hits, and the average percent identity of these hits was 41%. He goes on to note:
“This is the average similarity between proteins (gene products), not genes… Of course, there are many, many genes in our genome that do not have a recognizable counterpart in the banana genome and vice versa.”
So when we get to the bottom of it, the 50% figure is actually 40% average amino acid percent identity between 7000 blast hits of human and banana.
What do we mean when we say “we share 50% of our DNA with a banana”?
All living organisms descended from a common ancestor, and therefore all living organisms have some genes in common. What determines how many genes in common depends on how far back in time the two species shared a common ancestor. For example, humans and chimps share such a high percentage of genes, because we only diverged ~6 MYA1. However, human and banana (more specifically the common ancestors which led to human and banana) split around 1.5 BILLION years ago2. Talk about a banana split! Therefore we would expect a lot less to be conserved.
As brought up by Neil Saunders in his blog post, “What does ‘we share 50% of our DNA’ really mean?” A non-biologist perhaps might not see the nuance in this question. If I were going to play the devil’s advocate, I could say that a child shares 50% of its DNA with their parents. Or even that every organism shares 100% DNA, as it is all made up of Gs, Cs, As, and Ts. Thus, it is important to be specific on what we’re talking about.
This shared DNA could be referring to a number of things: protein-coding genes, non-coding genes, transposable elements, the percent that gets aligned in a whole genome alignment3, etc. Each of these specific features evolve at different rates, and thus will be more or less conserved between any given species.
Well, how do we know if these genomic features are conserved?
Generally, sequences are compared by making an alignment, and then computing the percent identity or evolutionary distance between the two sequences. If the sequences are sufficiently similar, they can be declared as conserved. Thus, “conserved” can be seen as either categorical (i.e. conserved or not), and then specified as a quantitative value (conserved to a certain degree). For more information, see the Wiki page on conserved sequences.
What are the genomic features the most likely to be conserved?
“Conservation indicates that a sequence has been maintained by natural selection” (wiki). Genes, or DNA sequences, encode for the proteins. Proteins are slower to evolve and change than the DNA, due to the redundancy of the genetic code. Thus proteins are the genomic feature most likely to be conserved between evolutionary distant species. While it is true that other genomic features such as non-coding regulatory sequences or non-coding RNA can be conserved over long evolutionary distances, they are far more likely to diverge in sequence than proteins4,5. Other genetic features such as transposable elements, or intergenic “junk DNA” are even less likely to be conserved, as their sequences are under less selection pressure and accumulate mutations at an even higher rate.
It is important to note that while we generally declare sequences to be conserved on the basis of sequence similarity, sequences may be still conserved and lack similarity. For example, two sequences might be conserved in the structure of the protein, indicating homology 6,7. Additionally, sequences might be in a syntenic position, indicating ancestral conservation, but may also lack sequence similarity 8. Thus, it is possible for some genes to be shared between evolutionary distant species, but they may fly under the radar of our current homology-inference tools. So, in order to investigate the 50% shared DNA claim, we can only focus on sequence conservation which we are able to detect.
To understand how much of the genome is conserved between banana and human, I will look at proteins because it’s the feature most likely to be conserved between human and banana. This is to be as permissive as possible in attempts to give the benefit of the doubt to the 50% meme.
Now the question is, how do we compare all the proteins in one species to all the proteins in another species and see which ones “match”, i.e. descended from a common ancestral gene? This is a fundamental problem important for studying evolution. Orthologs are the term we use for genes in different species that started diverging due to a speciation event, i.e. “corresponding” genes between species. This is where our lab’s expertise comes in: we maintain Orthologous Matrix, which is a method and database for finding orthologs between many species.
Orthologs in common between human and banana
I wanted to see what percent of human’s genes are orthologous to banana genes一and vice versa一what percent of banana’s genes are orthologous to human’s. To compare several different methods, I tested three common methods for finding orthologs: OMA9, OrthoInspector10, and best-bidirectional hit (using BLASTP)11. For each method, I divided the number of orthologs found by the number genes in the genome to come up with a percentage of each genome that is shared. You can find all the details here jupyter notebook, but the results are summed up in the graph below:
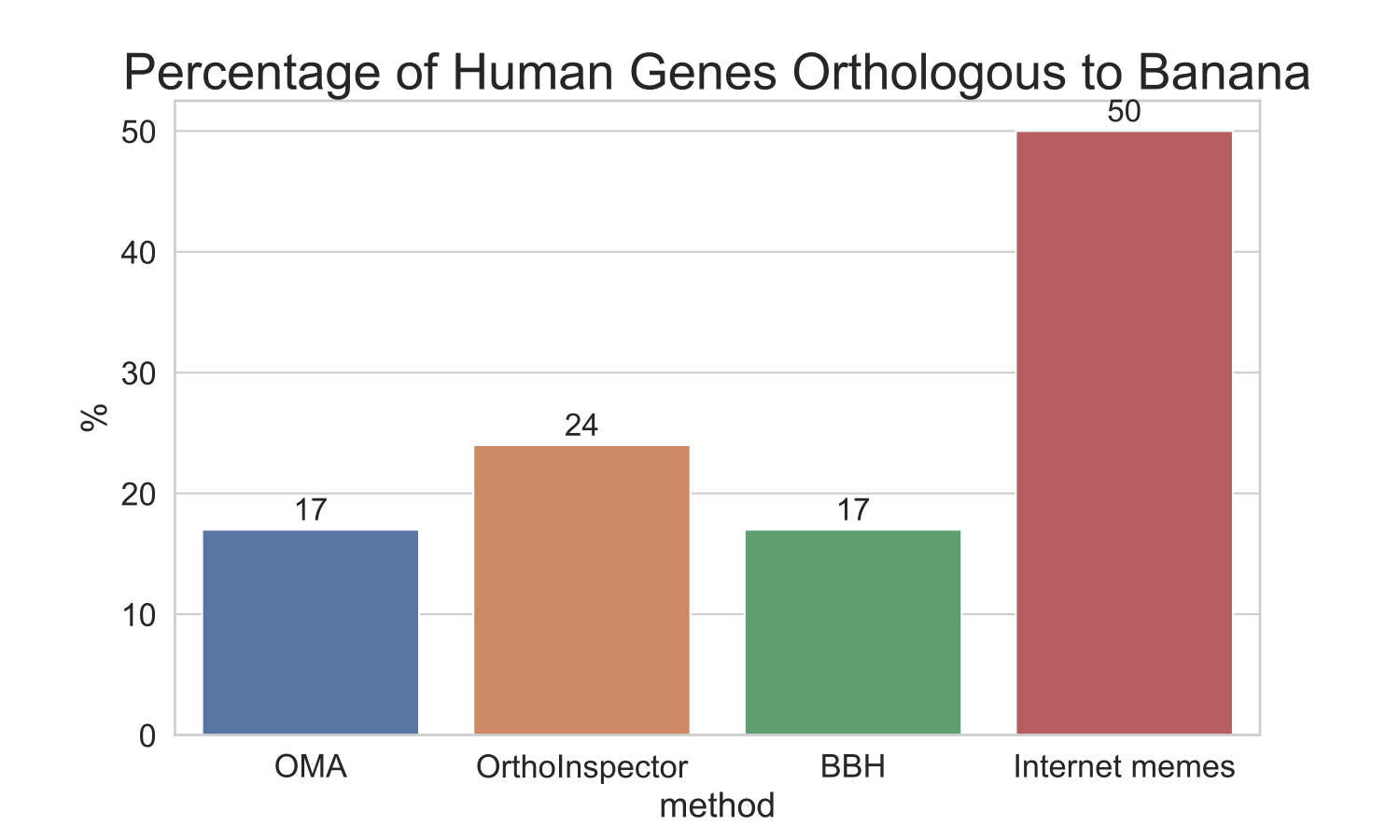
Comparison of ortholog methods
As you can see, all the orthology-inference methods tested show a maximum of 25% of human genes to be orthologous to banana. Again, these results give the most leeway, as we used protein sequences, which are the genomic elements the most likely to be conserved.
Additionally, I investigated the percentage of a whole-genome alignment that would be shared between banana and human. Since this is computationally intensive, I used Ensembl Compara, which has precomputed pairwise whole-genome alignments between a number of species. A whole-genome alignment looks at the whole genome, not just genes, as well as compares DNA rather than proteins. They didn’t have results between human and banana, but here are the results between human and chimp, mouse, and zebrafish:
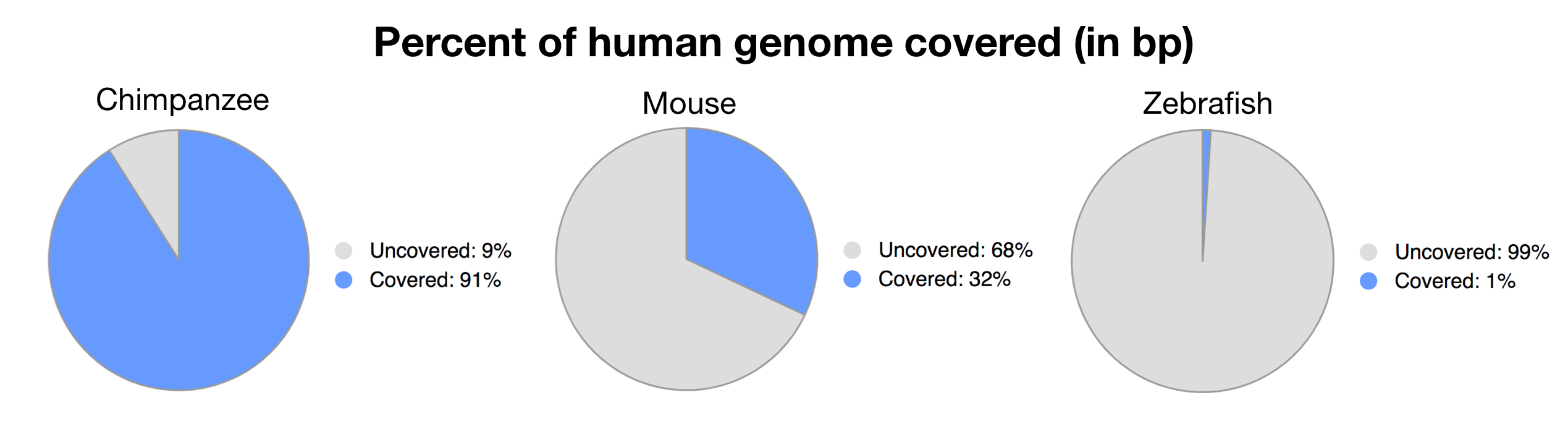
Data obtained from https://uswest.ensembl.org/info/genome/compara/analyses.html#
As we get progressively further in evolutionary distance, we get a smaller and smaller percentage of the genome which is able to be aligned. We can presume that plants would be even less than 1%, a far cry from the 50% as reported by internet memes.
So whichever way you slice it, humans share at most ¼, not ½ of its genetic material with banana (at least what we are able to detect)!
What do these human-banana orthologs DO?
Now that we have found the human-banana orthologs, we can try to gain some insight into what these genes do. To do this, I performed a Gene Ontology (GO) enrichment analysis of the human genes. GO enrichment works by assigning functional annotations to all of the sequences, then looking for a statistical overrepresentation of certain functions in a subset of genes compared to the entire genome.
I used the PANTHER Overrepresentation Test web server for the GO enrichment, then used GO-Figure12 for summarizing and visualizing the most enriched Biological Processes. All the details are in the jupyter notebook.
The top 10 overrepresented GO terms, i.e. a summary of the most common functions of the human genes with orthologs, is shown below:
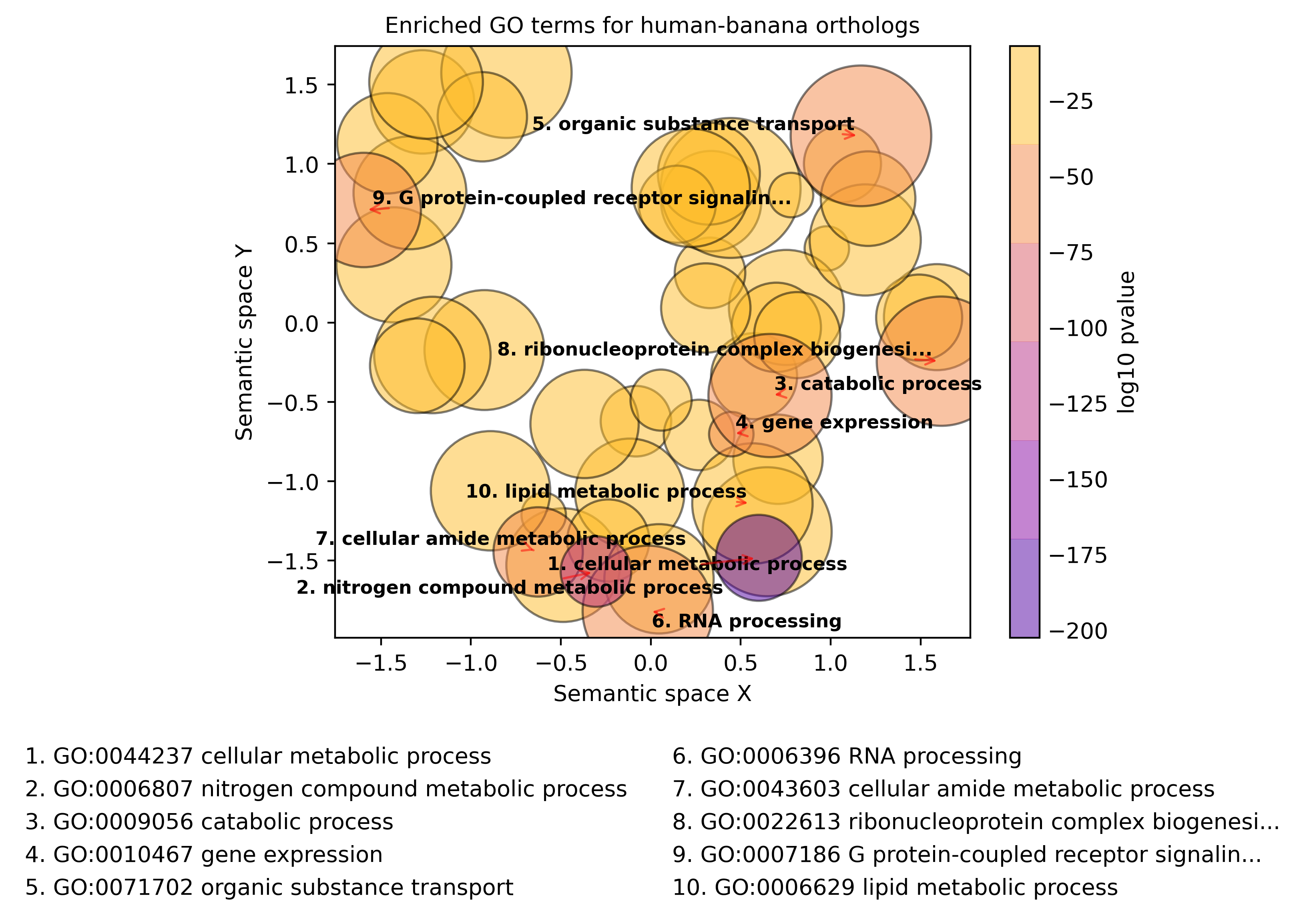
Top 10 overrepresented GO Biological Processes for human protein-coding genes with banana orthologs
We can see that the human-banana orthologs are highly enriched for basic, metabolic processes such as “cellular metabolic process,” “gene expression,” and “RNA processing.” These biological functions are likely genes which encode for cellular processes that are essential for eukaryotic life!
Take home message
- “Humans share 50% of DNA with banana” is a statement that has very little meaning.
- We must be careful to be precise in our language. We have to clarify what we mean when we give a percentage of “shared genetic material/DNA/genome.” I argue that the percentage of protein-coding genes is currently the best way to compare evolutionarily distant species
- There’s no evidence that humans have 50% of detectable orthologs with a banana. In my analysis, I show between 17 and 24%, depending on which method was used. As scientists, we have to do a better job communicating science with each other and with the general public.
Even though we don’t have 50% genes in common with banana, we still have ~20% which is nothing to scoff at! The functions of these genes are most likely basic housekeeping proteins involved in metabolic processes that are necessary for most, if not all of eukaryotic life. It is amazing that these genes have been conserved over 1.5 billion years of evolution!
References
- Patterson, N., Richter, D. J., Gnerre, S., Lander, E. S. & Reich, D. Genetic evidence for complex speciation of humans and chimpanzees. Nature 441, 1103–1108 (2006).
- Wang, D. Y., Kumar, S. & Hedges, S. B. Divergence time estimates for the early history of animal phyla and the origin of plants, animals and fungi. Proc. Biol. Sci. 266, 163–171 (1999).
- Armstrong, J., Fiddes, I. T., Diekhans, M. & Paten, B. Whole-Genome Alignment and Comparative Annotation. Annu Rev Anim Biosci 7, 41–64 (2019).
- Ransohoff, J. D., Wei, Y. & Khavari, P. A. The functions and unique features of long intergenic non-coding RNA. Nat. Rev. Mol. Cell Biol. 19, 143–157 (2018).
- Diederichs, S. The four dimensions of noncoding RNA conservation. Trends Genet. 30, 121–123 (2014).
- Illergård, K., Ardell, D. H. & Elofsson, A. Structure is three to ten times more conserved than sequence—a study of structural response in protein cores. Proteins 77, 499–508 (2009).
- Zheng, W. et al. Detecting distant-homology protein structures by aligning deep neural-network based contact maps. PLoS Comput. Biol. 15, e1007411 (2019).
- Vakirlis, N., Carvunis, A.-R. & McLysaght, A. Synteny-based analyses indicate that sequence divergence is not the main source of orphan genes. Cold Spring Harbor Laboratory 735175 (2019) doi:10.1101/735175.
- Altenhoff, A. M. et al. OMA orthology in 2021: website overhaul, conserved isoforms, ancestral gene order and more. Nucleic Acids Res. doi:10.1093/nar/gkaa1007.
- Nevers, Y. et al. OrthoInspector 3.0: open portal for comparative genomics. Nucleic Acids Res. 47, D411–D418 (2019).
- Moreno-Hagelsieb, G. & Latimer, K. Choosing BLAST options for better detection of orthologs as reciprocal best hits. Bioinformatics 24, 319–324 (2008).
- Reijnders, M. J. & Waterhouse, R. M. Summary Visualisations of Gene Ontology Terms with GO-Figure! Cold Spring Harbor Laboratory 2020.12.02.408534 (2020) doi:10.1101/2020.12.02.408534.